目錄
- 一、準備訓練數據
- 二、數據的處理和保存
- 2.1 小黃雞的語料的處理
- 2.2 微博語料的處理
- 2.3 處理后的結果
- 三、構造文本序列化和反序列化方法
- 四、構建Dataset和DataLoader
- 五、完成encoder編碼器邏輯
- 六、完成decoder解碼器的邏輯
- 七、完成seq2seq的模型
- 八、完成訓練邏輯
- 九、評估邏輯
一、準備訓練數據
主要的數據有兩個:
1.小黃雞的聊天語料:噪聲很大

2.微博的標題和評論:質量相對較高

二、數據的處理和保存
由于數據中存到大量的噪聲,可以對其進行基礎的處理,然后分別把input和target使用兩個文件保存,即input中的第N行尾問,target的第N行為答
后續可能會把單個字作為特征(存放在input_word.txt),也可能會把詞語作為特征(input.txt)
2.1 小黃雞的語料的處理
def format_xiaohuangji_corpus(word=False):
"""處理小黃雞的語料"""
if word:
corpus_path = "./chatbot/corpus/xiaohuangji50w_nofenci.conv"
input_path = "./chatbot/corpus/input_word.txt"
output_path = "./chatbot/corpus/output_word.txt"
else:
corpus_path = "./chatbot/corpus/xiaohuangji50w_nofenci.conv"
input_path = "./chatbot/corpus/input.txt"
output_path = "./chatbot/corpus/output.txt"
f_input = open(input_path, "a")
f_output = open(output_path, "a")
pair = []
for line in tqdm(open(corpus_path), ascii=True):
if line.strip() == "E":
if not pair:
continue
else:
assert len(pair) == 2, "長度必須是2"
if len(pair[0].strip()) >= 1 and len(pair[1].strip()) >= 1:
f_input.write(pair[0] + "\n")
f_output.write(pair[1] + "\n")
pair = []
elif line.startswith("M"):
line = line[1:]
if word:
pair.append(" ".join(list(line.strip())))
else:
pair.append(" ".join(jieba_cut(line.strip())))
2.2 微博語料的處理
def format_weibo(word=False):
"""
微博數據存在一些噪聲,未處理
:return:
"""
if word:
origin_input = "./chatbot/corpus/stc_weibo_train_post"
input_path = "./chatbot/corpus/input_word.txt"
origin_output = "./chatbot/corpus/stc_weibo_train_response"
output_path = "./chatbot/corpus/output_word.txt"
else:
origin_input = "./chatbot/corpus/stc_weibo_train_post"
input_path = "./chatbot/corpus/input.txt"
origin_output = "./chatbot/corpus/stc_weibo_train_response"
output_path = "./chatbot/corpus/output.txt"
f_input = open(input_path, "a")
f_output = open(output_path, "a")
with open(origin_input) as in_o, open(origin_output) as out_o:
for _in, _out in tqdm(zip(in_o, out_o), ascii=True):
_in = _in.strip()
_out = _out.strip()
if _in.endswith(")") or _in.endswith("」") or _in.endswith(")"):
_in = re.sub("(.*)|「.*?」|\(.*?\)", " ", _in)
_in = re.sub("我在.*?alink|alink|(.*?\d+x\d+.*?)|#|】|【|-+|_+|via.*?:*.*", " ", _in)
_in = re.sub("\s+", " ", _in)
if len(_in) 1 or len(_out) 1:
continue
if word:
_in = re.sub("\s+", "", _in) # 轉化為一整行,不含空格
_out = re.sub("\s+", "", _out)
if len(_in) >= 1 and len(_out) >= 1:
f_input.write(" ".join(list(_in)) + "\n")
f_output.write(" ".join(list(_out)) + "\n")
else:
if len(_in) >= 1 and len(_out) >= 1:
f_input.write(_in.strip() + "\n")
f_output.write(_out.strip() + "\n")
f_input.close()
f_output.close()
2.3 處理后的結果

三、構造文本序列化和反序列化方法
和之前的操作相同,需要把文本能轉化為數字,同時還需實現方法把數字轉化為文本
示例代碼:
import config
import pickle
class Word2Sequence():
UNK_TAG = "UNK"
PAD_TAG = "PAD"
SOS_TAG = "SOS"
EOS_TAG = "EOS"
UNK = 0
PAD = 1
SOS = 2
EOS = 3
def __init__(self):
self.dict = {
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD,
self.SOS_TAG: self.SOS,
self.EOS_TAG: self.EOS
}
self.count = {}
self.fited = False
def to_index(self, word):
"""word -> index"""
assert self.fited == True, "必須先進行fit操作"
return self.dict.get(word, self.UNK)
def to_word(self, index):
"""index -> word"""
assert self.fited, "必須先進行fit操作"
if index in self.inversed_dict:
return self.inversed_dict[index]
return self.UNK_TAG
def __len__(self):
return len(self.dict)
def fit(self, sentence):
"""
:param sentence:[word1,word2,word3]
:param min_count: 最小出現的次數
:param max_count: 最大出現的次數
:param max_feature: 總詞語的最大數量
:return:
"""
for a in sentence:
if a not in self.count:
self.count[a] = 0
self.count[a] += 1
self.fited = True
def build_vocab(self, min_count=1, max_count=None, max_feature=None):
# 比最小的數量大和比最大的數量小的需要
if min_count is not None:
self.count = {k: v for k, v in self.count.items() if v >= min_count}
if max_count is not None:
self.count = {k: v for k, v in self.count.items() if v = max_count}
# 限制最大的數量
if isinstance(max_feature, int):
count = sorted(list(self.count.items()), key=lambda x: x[1])
if max_feature is not None and len(count) > max_feature:
count = count[-int(max_feature):]
for w, _ in count:
self.dict[w] = len(self.dict)
else:
for w in sorted(self.count.keys()):
self.dict[w] = len(self.dict)
# 準備一個index->word的字典
self.inversed_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transform(self, sentence, max_len=None, add_eos=False):
"""
實現吧句子轉化為數組(向量)
:param sentence:
:param max_len:
:return:
"""
assert self.fited, "必須先進行fit操作"
r = [self.to_index(i) for i in sentence]
if max_len is not None:
if max_len > len(sentence):
if add_eos:
r += [self.EOS] + [self.PAD for _ in range(max_len - len(sentence) - 1)]
else:
r += [self.PAD for _ in range(max_len - len(sentence))]
else:
if add_eos:
r = r[:max_len - 1]
r += [self.EOS]
else:
r = r[:max_len]
else:
if add_eos:
r += [self.EOS]
# print(len(r),r)
return r
def inverse_transform(self, indices):
"""
實現從數組 轉化為 向量
:param indices: [1,2,3....]
:return:[word1,word2.....]
"""
sentence = []
for i in indices:
word = self.to_word(i)
sentence.append(word)
return sentence
# 之后導入該word_sequence使用
word_sequence = pickle.load(open("./pkl/ws.pkl", "rb")) if not config.use_word else pickle.load(
open("./pkl/ws_word.pkl", "rb"))
if __name__ == '__main__':
from word_sequence import Word2Sequence
from tqdm import tqdm
import pickle
word_sequence = Word2Sequence()
# 詞語級別
input_path = "../corpus/input.txt"
target_path = "../corpus/output.txt"
for line in tqdm(open(input_path).readlines()):
word_sequence.fit(line.strip().split())
for line in tqdm(open(target_path).readlines()):
word_sequence.fit(line.strip().split())
# 使用max_feature=5000個數據
word_sequence.build_vocab(min_count=5, max_count=None, max_feature=5000)
print(len(word_sequence))
pickle.dump(word_sequence, open("./pkl/ws.pkl", "wb"))
word_sequence.py:
class WordSequence(object):
PAD_TAG = 'PAD' # 填充標記
UNK_TAG = 'UNK' # 未知詞標記
SOS_TAG = 'SOS' # start of sequence
EOS_TAG = 'EOS' # end of sequence
PAD = 0
UNK = 1
SOS = 2
EOS = 3
def __init__(self):
self.dict = {
self.PAD_TAG: self.PAD,
self.UNK_TAG: self.UNK,
self.SOS_TAG: self.SOS,
self.EOS_TAG: self.EOS
}
self.count = {} # 保存詞頻詞典
self.fited = False
def to_index(self, word):
"""
word --> index
:param word:
:return:
"""
assert self.fited == True, "必須先進行fit操作"
return self.dict.get(word, self.UNK)
def to_word(self, index):
"""
index -- > word
:param index:
:return:
"""
assert self.fited, '必須先進行fit操作'
if index in self.inverse_dict:
return self.inverse_dict[index]
return self.UNK_TAG
def fit(self, sentence):
"""
傳入句子,統計詞頻
:param sentence:
:return:
"""
for word in sentence:
# 對word出現的頻率進行統計,當word不在sentence時,返回值是0,當word在sentence中時,返回+1,以此進行累計計數
# self.count[word] = self.dict.get(word, 0) + 1
if word not in self.count:
self.count[word] = 0
self.count[word] += 1
self.fited = True
def build_vocab(self, min_count=2, max_count=None, max_features=None):
"""
構造詞典
:param min_count:最小詞頻
:param max_count: 最大詞頻
:param max_features: 詞典中詞的數量
:return:
"""
# self.count.pop(key),和del self.count[key] 無法在遍歷self.count的同時進行刪除key.因此淺拷貝temp后對temp遍歷并刪除self.count
temp = self.count.copy()
for key in temp:
cur_count = self.count.get(key, 0) # 當前詞頻
if min_count is not None:
if cur_count min_count:
del self.count[key]
if max_count is not None:
if cur_count > max_count:
del self.count[key]
if max_features is not None:
self.count = dict(sorted(list(self.count.items()), key=lambda x: x[1], reversed=True)[:max_features])
for key in self.count:
self.dict[key] = len(self.dict)
# 準備一個index-->word的字典
self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transforms(self, sentence, max_len=10, add_eos=False):
"""
把sentence轉化為序列
:param sentence: 傳入的句子
:param max_len: 句子的最大長度
:param add_eos: 是否添加結束符
add_eos : True時,輸出句子長度為max_len + 1
add_eos : False時,輸出句子長度為max_len
:return:
"""
assert self.fited, '必須先進行fit操作!'
if len(sentence) > max_len:
sentence = sentence[:max_len]
# 提前計算句子長度,實現ass_eos后,句子長度統一
sentence_len = len(sentence)
# sentence[1,3,4,5,UNK,EOS,PAD,....]
if add_eos:
sentence += [self.EOS_TAG]
if sentence_len max_len:
# 句子長度不夠,用PAD來填充
sentence += (max_len - sentence_len) * [self.PAD_TAG]
# 對于新出現的詞采用特殊標記
result = [self.dict.get(i, self.UNK) for i in sentence]
return result
def invert_transform(self, indices):
"""
序列轉化為sentence
:param indices:
:return:
"""
# return [self.inverse_dict.get(i, self.UNK_TAG) for i in indices]
result = []
for i in indices:
if self.inverse_dict[i] == self.EOS_TAG:
break
result.append(self.inverse_dict.get(i, self.UNK_TAG))
return result
def __len__(self):
return len(self.dict)
if __name__ == '__main__':
num_sequence = WordSequence()
print(num_sequence.dict)
str1 = ['中國', '您好', '我愛你', '中國', '我愛你', '北京']
num_sequence.fit(str1)
num_sequence.build_vocab()
print(num_sequence.transforms(str1))
print(num_sequence.dict)
print(num_sequence.inverse_dict)
print(num_sequence.invert_transform([5, 4])) # 這兒要傳列表
運行結果:

四、構建Dataset和DataLoader
創建dataset.py 文件,準備數據集
import config
import torch
from torch.utils.data import Dataset, DataLoader
from word_sequence import WordSequence
class ChatDataset(Dataset):
def __init__(self):
self.input_path = config.chatbot_input_path
self.target_path = config.chatbot_target_path
self.input_lines = open(self.input_path, encoding='utf-8').readlines()
self.target_lines = open(self.target_path, encoding='utf-8').readlines()
assert len(self.input_lines) == len(self.target_lines), 'input和target長度不一致'
def __getitem__(self, item):
input = self.input_lines[item].strip().split()
target = self.target_lines[item].strip().split()
if len(input) == 0 or len(target) == 0:
input = self.input_lines[item + 1].strip().split()
target = self.target_lines[item + 1].strip().split()
# 此處句子的長度如果大于max_len,那么應該返回max_len
input_length = min(len(input), config.max_len)
target_length = min(len(target), config.max_len)
return input, target, input_length, target_length
def __len__(self):
return len(self.input_lines)
def collate_fn(batch):
# 1.排序
batch = sorted(batch, key=lambda x: x[2], reversed=True)
input, target, input_length, target_length = zip(*batch)
# 2.進行padding的操作
input = torch.LongTensor([WordSequence.transform(i, max_len=config.max_len) for i in input])
target = torch.LongTensor([WordSequence.transforms(i, max_len=config.max_len, add_eos=True) for i in target])
input_length = torch.LongTensor(input_length)
target_length = torch.LongTensor(target_length)
return input, target, input_length, target_length
data_loader = DataLoader(dataset=ChatDataset(), batch_size=config.batch_size, shuffle=True, collate_fn=collate_fn,
drop_last=True)
if __name__ == '__main__':
print(len(data_loader))
for idx, (input, target, input_length, target_length) in enumerate(data_loader):
print(idx)
print(input)
print(target)
print(input_length)
print(target_length)
五、完成encoder編碼器邏輯
encode.py:
import torch.nn as nn
import config
from torch.nn.utils.rnn import pad_packed_sequence, pack_padded_sequence
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
# torch.nn.Embedding(num_embeddings詞典大小即不重復詞數,embedding_dim單個詞用多長向量表示)
self.embedding = nn.Embedding(
num_embeddings=len(config.word_sequence.dict),
embedding_dim=config.embedding_dim,
padding_idx=config.word_sequence.PAD
)
self.gru = nn.GRU(
input_size=config.embedding_dim,
num_layers=config.num_layer,
hidden_size=config.hidden_size,
bidirectional=False,
batch_first=True
)
def forward(self, input, input_length):
"""
:param input: [batch_size, max_len]
:return:
"""
embedded = self.embedding(input) # embedded [batch_size, max_len, embedding_dim]
# 加速循環過程
embedded = pack_padded_sequence(embedded, input_length, batch_first=True) # 打包
out, hidden = self.gru(embedded)
out, out_length = pad_packed_sequence(out, batch_first=True, padding_value=config.num_sequence.PAD) # 解包
# hidden即h_n [num_layer*[1/2],batchsize, hidden_size]
# out : [batch_size, seq_len/max_len, hidden_size]
return out, hidden, out_length
if __name__ == '__main__':
from dataset import data_loader
encoder = Encoder()
print(encoder)
for input, target, input_length, target_length in data_loader:
out, hidden, out_length = encoder(input, input_length)
print(input.size())
print(out.size())
print(hidden.size())
print(out_length)
break
六、完成decoder解碼器的邏輯
decode.py:
import torch
import torch.nn as nn
import config
import torch.nn.functional as F
from word_sequence import WordSequence
class Decode(nn.Module):
def __init__(self):
super().__init__()
self.max_seq_len = config.max_len
self.vocab_size = len(WordSequence)
self.embedding_dim = config.embedding_dim
self.dropout = config.dropout
self.embedding = nn.Embedding(num_embeddings=self.vocab_size, embedding_dim=self.embedding_dim,
padding_idx=WordSequence.PAD)
self.gru = nn.GRU(input_size=self.embedding_dim, hidden_size=config.hidden_size, num_layers=1, batch_first=True,
dropout=self.dropout)
self.log_softmax = nn.LogSoftmax()
self.fc = nn.Linear(config.hidden_size, self.vocab_size)
def forward(self, encoder_hidden, target, target_length):
# encoder_hidden [batch_size,hidden_size]
# target [batch_size,seq-len]
decoder_input = torch.LongTensor([[WordSequence.SOS]] * config.batch_size).to(config.device)
decoder_outputs = torch.zeros(config.batch_size, config.max_len, self.vocab_size).to(
config.device) # [batch_size,seq_len,14]
decoder_hidden = encoder_hidden # [batch_size,hidden_size]
for t in range(config.max_len):
decoder_output_t, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs[:, t, :] = decoder_output_t
value, index = torch.topk(decoder_output_t, 1) # index [batch_size,1]
decoder_input = index
return decoder_outputs, decoder_hidden
def forward_step(self, decoder_input, decoder_hidden):
"""
:param decoder_input:[batch_size,1]
:param decoder_hidden:[1,batch_size,hidden_size]
:return:[batch_size,vocab_size],decoder_hidden:[1,batch_size,didden_size]
"""
embeded = self.embedding(decoder_input) # embeded: [batch_size,1 , embedding_dim]
out, decoder_hidden = self.gru(embeded, decoder_hidden) # out [1, batch_size, hidden_size]
out = out.squeeze(0)
out = F.log_softmax(self.fc(out), dim=1) # [batch_Size, vocab_size]
out = out.squeeze(0)
# print("out size:",out.size(),decoder_hidden.size())
return out, decoder_hidden
關于 decoder_outputs[:,t,:] = decoder_output_t的演示
decoder_outputs 形狀 [batch_size, seq_len, vocab_size]
decoder_output_t 形狀[batch_size, vocab_size]
示例代碼:
import torch
a = torch.zeros((2, 3, 5))
print(a.size())
print(a)
b = torch.randn((2, 5))
print(b.size())
print(b)
a[:, 0, :] = b
print(a.size())
print(a)
運行結果:

關于torch.topk, torch.max(),torch.argmax()
value, index = torch.topk(decoder_output_t , k = 1)
decoder_output_t [batch_size, vocab_size]
示例代碼:
import torch
a = torch.randn((3, 5))
print(a.size())
print(a)
values, index = torch.topk(a, k=1)
print(values)
print(index)
print(index.size())
values, index = torch.max(a, dim=-1)
print(values)
print(index)
print(index.size())
index = torch.argmax(a, dim=-1)
print(index)
print(index.size())
index = a.argmax(dim=-1)
print(index)
print(index.size())
運行結果:

若使用teacher forcing ,將采用下次真實值作為下個time step的輸入
# 注意unsqueeze 相當于淺拷貝,不會對原張量進行修改
decoder_input = target[:,t].unsqueeze(-1)
target 形狀 [batch_size, seq_len]
decoder_input 要求形狀[batch_size, 1]
示例代碼:
import torch
a = torch.randn((3, 5))
print(a.size())
print(a)
b = a[:, 3]
print(b.size())
print(b)
c = b.unsqueeze(-1)
print(c.size())
print(c)
運行結果:

七、完成seq2seq的模型
seq2seq.py:
import torch
import torch.nn as nn
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input, target, input_length, target_length):
encoder_outputs, encoder_hidden = self.encoder(input, input_length)
decoder_outputs, decoder_hidden = self.decoder(encoder_hidden, target, target_length)
return decoder_outputs, decoder_hidden
def evaluation(self, inputs, input_length):
encoder_outputs, encoder_hidden = self.encoder(inputs, input_length)
decoded_sentence = self.decoder.evaluation(encoder_hidden)
return decoded_sentence
八、完成訓練邏輯
為了加速訓練,可以考慮在gpu上運行,那么在我們自頂一個所以的tensor和model都需要轉化為CUDA支持的類型。
當前的數據量為500多萬條,在GTX1070(8G顯存)上訓練,大概需要90分一個epoch,耐心的等待吧
train.py:
import torch
import config
from torch import optim
import torch.nn as nn
from encode import Encoder
from decode import Decoder
from seq2seq import Seq2Seq
from dataset import data_loader as train_dataloader
from word_sequence import WordSequence
encoder = Encoder()
decoder = Decoder()
model = Seq2Seq(encoder, decoder)
# device在config文件中實現
model.to(config.device)
print(model)
model.load_state_dict(torch.load("model/seq2seq_model.pkl"))
optimizer = optim.Adam(model.parameters())
optimizer.load_state_dict(torch.load("model/seq2seq_optimizer.pkl"))
criterion = nn.NLLLoss(ignore_index=WordSequence.PAD, reduction="mean")
def get_loss(decoder_outputs, target):
target = target.view(-1) # [batch_size*max_len]
decoder_outputs = decoder_outputs.view(config.batch_size * config.max_len, -1)
return criterion(decoder_outputs, target)
def train(epoch):
for idx, (input, target, input_length, target_len) in enumerate(train_dataloader):
input = input.to(config.device)
target = target.to(config.device)
input_length = input_length.to(config.device)
target_len = target_len.to(config.device)
optimizer.zero_grad()
##[seq_len,batch_size,vocab_size] [batch_size,seq_len]
decoder_outputs, decoder_hidden = model(input, target, input_length, target_len)
loss = get_loss(decoder_outputs, target)
loss.backward()
optimizer.step()
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, idx * len(input), len(train_dataloader.dataset),
100. * idx / len(train_dataloader), loss.item()))
torch.save(model.state_dict(), "model/seq2seq_model.pkl")
torch.save(optimizer.state_dict(), 'model/seq2seq_optimizer.pkl')
if __name__ == '__main__':
for i in range(10):
train(i)
訓練10個epoch之后的效果如下,可以看出損失依然很高:
Train Epoch: 9 [2444544/4889919 (50%)] Loss: 4.923604
Train Epoch: 9 [2444800/4889919 (50%)] Loss: 4.364594
Train Epoch: 9 [2445056/4889919 (50%)] Loss: 4.613254
Train Epoch: 9 [2445312/4889919 (50%)] Loss: 4.143538
Train Epoch: 9 [2445568/4889919 (50%)] Loss: 4.412729
Train Epoch: 9 [2445824/4889919 (50%)] Loss: 4.516526
Train Epoch: 9 [2446080/4889919 (50%)] Loss: 4.124945
Train Epoch: 9 [2446336/4889919 (50%)] Loss: 4.777015
Train Epoch: 9 [2446592/4889919 (50%)] Loss: 4.358538
Train Epoch: 9 [2446848/4889919 (50%)] Loss: 4.513412
Train Epoch: 9 [2447104/4889919 (50%)] Loss: 4.202757
Train Epoch: 9 [2447360/4889919 (50%)] Loss: 4.589584
九、評估邏輯
decoder 中添加評估方法
def evaluate(self, encoder_hidden):
"""
評估, 和fowward邏輯類似
:param encoder_hidden: encoder最后time step的隱藏狀態 [1, batch_size, hidden_size]
:return:
"""
batch_size = encoder_hidden.size(1)
# 初始化一個[batch_size, 1]的SOS張量,作為第一個time step的輸出
decoder_input = torch.LongTensor([[config.target_ws.SOS]] * batch_size).to(config.device)
# encoder_hidden 作為decoder第一個時間步的hidden [1, batch_size, hidden_size]
decoder_hidden = encoder_hidden
# 初始化[batch_size, seq_len, vocab_size]的outputs 拼接每個time step結果
decoder_outputs = torch.zeros((batch_size, config.chatbot_target_max_len, self.vocab_size)).to(config.device)
# 初始化一個空列表,存儲每次的預測序列
predict_result = []
# 對每個時間步進行更新
for t in range(config.chatbot_target_max_len):
decoder_output_t, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
# 拼接每個time step,decoder_output_t [batch_size, vocab_size]
decoder_outputs[:, t, :] = decoder_output_t
# 由于是評估,需要每次都獲取預測值
index = torch.argmax(decoder_output_t, dim = -1)
# 更新下一時間步的輸入
decoder_input = index.unsqueeze(1)
# 存儲每個時間步的預測序列
predict_result.append(index.cpu().detach().numpy()) # [[batch], [batch]...] ->[seq_len, vocab_size]
# 結果轉換為ndarry,每行是一個預測結果即單個字對應的索引, 所有行為seq_len長度
predict_result = np.array(predict_result).transpose() # (batch_size, seq_len)的array
return decoder_outputs, predict_result
eval.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from dataset import get_dataloader
import config
import numpy as np
from Seq2Seq import Seq2SeqModel
import os
from tqdm import tqdm
model = Seq2SeqModel().to(config.device)
if os.path.exists('./model/chatbot_model.pkl'):
model.load_state_dict(torch.load('./model/chatbot_model.pkl'))
def eval():
model.eval()
loss_list = []
test_data_loader = get_dataloader(train = False)
with torch.no_grad():
bar = tqdm(test_data_loader, desc = 'testing', total = len(test_data_loader))
for idx, (input, target, input_length, target_length) in enumerate(bar):
input = input.to(config.device)
target = target.to(config.device)
input_length = input_length.to(config.device)
target_length = target_length.to(config.device)
# 獲取模型的預測結果
decoder_outputs, predict_result = model.evaluation(input, input_length)
# 計算損失
loss = F.nll_loss(decoder_outputs.view(-1, len(config.target_ws)), target.view(-1), ignore_index = config.target_ws.PAD)
loss_list.append(loss.item())
bar.set_description('idx{}:/{}, loss:{}'.format(idx, len(test_data_loader), np.mean(loss_list)))
if __name__ == '__main__':
eval()
interface.py:
from cut_sentence import cut
import torch
import config
from Seq2Seq import Seq2SeqModel
import os
# 模擬聊天場景,對用戶輸入進來的話進行回答
def interface():
# 加載訓練集好的模型
model = Seq2SeqModel().to(config.device)
assert os.path.exists('./model/chatbot_model.pkl') , '請先對模型進行訓練!'
model.load_state_dict(torch.load('./model/chatbot_model.pkl'))
model.eval()
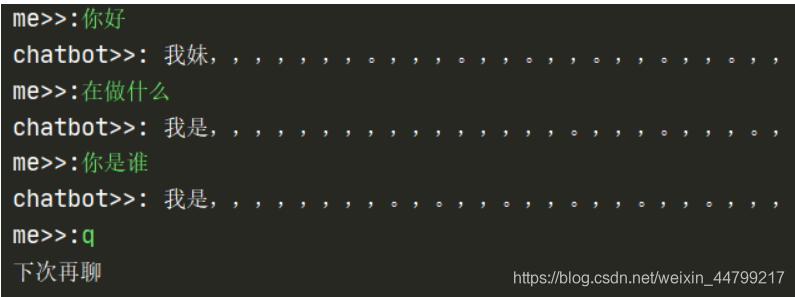
while True:
# 輸入進來的原始字符串,進行分詞處理
input_string = input('me>>:')
if input_string == 'q':
print('下次再聊')
break
input_cuted = cut(input_string, by_word = True)
# 進行序列轉換和tensor封裝
input_tensor = torch.LongTensor([config.input_ws.transfrom(input_cuted, max_len = config.chatbot_input_max_len)]).to(config.device)
input_length_tensor = torch.LongTensor([len(input_cuted)]).to(config.device)
# 獲取預測結果
outputs, predict = model.evaluation(input_tensor, input_length_tensor)
# 進行序列轉換文本
result = config.target_ws.inverse_transform(predict[0])
print('chatbot>>:', result)
if __name__ == '__main__':
interface()
config.py:
import torch
from word_sequence import WordSequence
chatbot_input_path = './corpus/input.txt'
chatbot_target_path = './corpus/target.txt'
word_sequence = WordSequence()
max_len = 9
batch_size = 128
embedding_dim = 100
num_layer = 1
hidden_size = 64
dropout = 0.1
model_save_path = './model.pkl'
optimizer_save_path = './optimizer.pkl'
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
cut.py:
"""
分詞
"""
import jieba
import config1
import string
import jieba.posseg as psg # 返回詞性
from lib.stopwords import stopwords
# 加載詞典
jieba.load_userdict(config1.user_dict_path)
# 準備英文字符
letters = string.ascii_lowercase + '+'
def cut_sentence_by_word(sentence):
"""實現中英文分詞"""
temp = ''
result = []
for word in sentence:
if word.lower() in letters:
# 如果是英文字符,則進行拼接空字符串
temp += word
else:
# 遇到漢字后,把英文先添加到結果中
if temp != '':
result.append(temp.lower())
temp = ''
result.append(word.strip())
if temp != '':
# 若英文出現在最后
result.append(temp.lower())
return result
def cut(sentence, by_word=False, use_stopwords=True, with_sg=False):
"""
:param sentence: 句子
:param by_word: T根據單個字分詞或者F句子
:param use_stopwords: 是否使用停用詞,默認False
:param with_sg: 是否返回詞性
:return:
"""
if by_word:
result = cut_sentence_by_word(sentence)
else:
result = psg.lcut(sentence)
# psg 源碼返回i.word,i.flag 即詞,定義的詞性
result = [(i.word, i.flag) for i in result]
# 是否返回詞性
if not with_sg:
result = [i[0] for i in result]
# 是否使用停用詞
if use_stopwords:
result = [i for i in result if i not in stopwords]
return result
到此這篇關于python通過Seq2Seq實現閑聊機器人的文章就介紹到這了,更多相關Seq2Seq實現閑聊機器人內容請搜索腳本之家以前的文章或繼續瀏覽下面的相關文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- 教你如何使用Python開發一個釘釘群應答機器人
- 用Python selenium實現淘寶搶單機器人
- python操作微信自動發消息的實現(微信聊天機器人)
- Python實現發票自動校核微信機器人的方法
- Python實現生活常識解答機器人
