前言
文章抄襲在互聯(lián)網(wǎng)中普遍存在,很多博主都收受其煩。近幾年隨著互聯(lián)網(wǎng)的發(fā)展,抄襲等不道德行為在互聯(lián)網(wǎng)上愈演愈烈,甚至復(fù)制、黏貼后發(fā)布標(biāo)原創(chuàng)屢見不鮮,部分抄襲后的文章甚至標(biāo)記了一些聯(lián)系方式從而使讀者獲取源碼等資料。這種惡劣的行為使人憤慨。
本文使用搜索引擎結(jié)果作為文章庫,再與本地或互聯(lián)網(wǎng)上數(shù)據(jù)做相似度對比,實(shí)現(xiàn)文章查重;由于查重的實(shí)現(xiàn)過程與一般情況下的微博情感分析實(shí)現(xiàn)流程相似,從而輕易的擴(kuò)展出情感分析功能(下一篇將在此篇代碼的基礎(chǔ)上完成數(shù)據(jù)采集、清洗到情感分析的整個過程)。
由于近期時間上并不充裕,暫時實(shí)現(xiàn)了主要功能,細(xì)節(jié)上并沒有進(jìn)行優(yōu)化,但是在代碼結(jié)構(gòu)上進(jìn)行了一些簡要的設(shè)計(jì),使得之后的功能擴(kuò)展、升級更為簡便。我本人也將會持續(xù)更新該工具的功能,爭取讓這個工具在技術(shù)上更加的成熟、實(shí)用。
技術(shù)
本文實(shí)現(xiàn)的查重功能為了考慮適配大多數(shù)站點(diǎn),從而使用selenium用作數(shù)據(jù)獲取,配置不同搜索引擎的信息,實(shí)現(xiàn)較為通用的搜索引擎查詢,并且不需要考慮過多的動態(tài)數(shù)據(jù)抓取;分詞主要使用jieba庫,完成對中文語句的分詞;使用余弦相似度完成文本相似度的對比并導(dǎo)出對比數(shù)據(jù)至Excel文章留作舉報(bào)信息。
微博情感分析基于sklearn,使用樸素貝葉斯完成對數(shù)據(jù)的情感分析;在數(shù)據(jù)抓取上,實(shí)現(xiàn)流程與文本查重的功能類似。
測試代碼獲取
CSDN codechina 代碼倉庫:https://codechina.csdn.net/A757291228/s-analysetooldemo
環(huán)境
作者的環(huán)境說明如下:
- 操作系統(tǒng):Windows7 SP1 64
- python 版本:3.7.7
- 瀏覽器:谷歌瀏覽器
- 瀏覽器版本: 80.0.3987 (64 位)
如有錯誤歡迎指出,歡迎留言交流。
一、實(shí)現(xiàn)文本查重
1.1 selenium安裝配置
由于使用的selenium,在使用前需要確保讀者是否已安裝selenium,使用pip命令,安裝如下:
安裝完成 Selenium 還需要下載一個驅(qū)動。
- 谷歌瀏覽器驅(qū)動:驅(qū)動版本需要對應(yīng)瀏覽器版本,不同的瀏覽器使用對應(yīng)不同版本的驅(qū)動,點(diǎn)擊下載
- 如果是使用火狐瀏覽器,查看火狐瀏覽器版本,點(diǎn)擊
GitHub火狐驅(qū)動下載地址
下載(英文不好的同學(xué)右鍵一鍵翻譯即可,每個版本都有對應(yīng)瀏覽器版本的使用說明,看清楚下載即可)
安裝了selenium后新建一python文件名為selenium_search,先在代碼中引入
from selenium import webdriver
可能有些讀者沒有把驅(qū)動配置到環(huán)境中,接下來我們可以指定驅(qū)動的位置(博主已配置到環(huán)境中):
driver = webdriver.Chrome(executable_path=r'F:\python\dr\chromedriver_win32\chromedriver.exe')
新建一個變量url賦值為百度首頁鏈接,使用get方法傳入url地址,嘗試打開百度首頁,完整代碼如下:
from selenium import webdriver
url='https://www.baidu.com'
driver=webdriver.Chrome()
driver.get(url)
在小黑框中使用命令行運(yùn)行python文件(windows下):

運(yùn)行腳本后將會打開谷歌瀏覽器并跳轉(zhuǎn)至百度首頁:

這樣就成功使用selenium打開了指定網(wǎng)址,接下來將指定搜索關(guān)鍵詞查詢得到結(jié)果,再從結(jié)果中遍歷到相似數(shù)據(jù)。
1.2 selenium百度搜索引擎關(guān)鍵詞搜索
在自動操控瀏覽器進(jìn)行關(guān)鍵字鍵入到搜索框前,需要獲取搜索框元素對象。使用谷歌瀏覽器打開百度首頁,右鍵搜索框選擇查看,將會彈出網(wǎng)頁元素(代碼)查看視窗,找到搜索框元素(使用鼠標(biāo)在元素節(jié)點(diǎn)中移動,鼠標(biāo)當(dāng)前位置的元素節(jié)點(diǎn)將會對應(yīng)的在網(wǎng)頁中標(biāo)藍(lán)):

在html代碼中,id的值大多數(shù)情況下唯一(除非是打錯了),在此選擇id作為獲取搜索框元素對象的標(biāo)記。selenium提供了find_element_by_id方法,可以通過傳入id獲取到網(wǎng)頁元素對象。
input=driver.find_element_by_id('kw')
獲取元素對象后,使用send_keys方法可傳入需要鍵入的值:
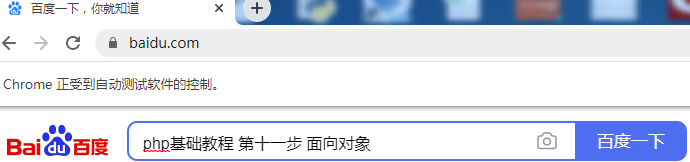
input.send_keys('php基礎(chǔ)教程 第十一步 面向?qū)ο?)
在此我傳入了 “php基礎(chǔ)教程 第十一步 面向?qū)ο?/strong>”作為關(guān)鍵字作為搜索。運(yùn)行腳本查看是否在搜索框中鍵入了關(guān)鍵字。代碼如下:
input.send_keys('php基礎(chǔ)教程 第十一步 面向?qū)ο?)
成功打開瀏覽器并鍵入了搜索關(guān)鍵字:
現(xiàn)在還差點(diǎn)擊“百度一下”按鈕完成最終的搜索。使用與查看搜索框相同的元素查看方法查找“百度一下”按鈕的id值:

使用find_element_by_id方法獲取到該元素對象,隨后使用click方法使該按鈕完成點(diǎn)擊操作:
search_btn=driver.find_element_by_id('su')
search_btn.click()
完整代碼如下:
from selenium import webdriver
url='https://www.baidu.com'
driver=webdriver.Chrome()
driver.get(url)
input=driver.find_element_by_id('kw')
input.send_keys('php基礎(chǔ)教程 第十一步 面向?qū)ο?)
search_btn=driver.find_element_by_id('su')
search_btn.click()
瀏覽器自動完成了鍵入搜索關(guān)鍵字及搜索功能:
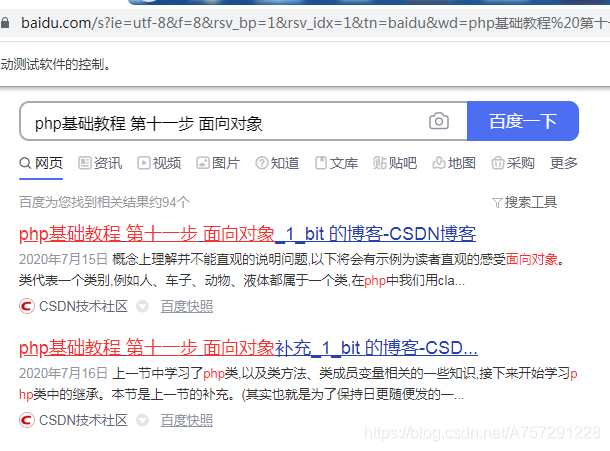
1.3 搜索結(jié)果遍歷
當(dāng)前已在瀏覽器中得到了搜索結(jié)果,接下來需要獲取整個web頁面內(nèi)容,得到搜索結(jié)果。使用selenium并不能很方便的獲取到,在這里使用BeautifulSoup對整個web頁面進(jìn)行解析并獲取搜索結(jié)果。
BeautifulSoup是一個HTML/XML解析器,使用BeautifulSoup會極大的方便我們對整個html的信息獲取。
使用BeautifulSoup前需確保已安裝。安裝命令如下:
pip install BeautifulSoup
安裝后,在當(dāng)前python文件頭部引入:
from bs4 import BeautifulSoup
獲取html文本可以調(diào)用page_source即可:
得到了html代碼后,新建BeautifulSoup對象,傳入html內(nèi)容并且指定解析器,這里指定使用 html.parser 解析器:
soup = BeautifulSoup(html, "html.parser")
接下來查看搜索內(nèi)容,發(fā)現(xiàn)所有的結(jié)果都由一個h標(biāo)簽包含,并且class為t:

BeautifulSoup提供了select方法對標(biāo)簽進(jìn)行獲取,支持通過類名、標(biāo)簽名、id、屬性、組合查找等。我們發(fā)現(xiàn)百度搜索結(jié)果中,結(jié)果皆有一個class =“t”,此時可以通過類名進(jìn)行遍歷獲取最為簡便:
search_res_list=soup.select('.t')
在select方法中傳入類名t,在類名前加上一個點(diǎn)(.)表示是通過類名獲取元素。
完成這一步后可以添加print嘗試打印出結(jié)果:
一般情況下,可能輸出search_res_list為空列表,這是因?yàn)槲覀冊跒g覽器解析數(shù)據(jù)渲染到瀏覽器前已經(jīng)獲取了瀏覽器當(dāng)前頁的內(nèi)容,這時有一個簡單的方法可以解決這個問題,但是此方法效率卻不高,在此只是暫時使用,之后將會用其它效率高于此方法的代碼替換(使用time需要在頭部引入):
完整代碼如下:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
url='https://www.baidu.com'
driver=webdriver.Chrome()
driver.get(url)
input=driver.find_element_by_id('kw')
input.send_keys('php基礎(chǔ)教程 第十一步 面向?qū)ο?)
search_btn=driver.find_element_by_id('su')
search_btn.click()
time.sleep(2)#在此等待 使瀏覽器解析并渲染到瀏覽器
html=driver.page_source #獲取網(wǎng)頁內(nèi)容
soup = BeautifulSoup(html, "html.parser")
search_res_list=soup.select('.t')
print(search_res_list)
運(yùn)行程序?qū)敵鰞?nèi)容:

獲取到的結(jié)果為所有class為t的標(biāo)簽,包括該標(biāo)簽的子節(jié)點(diǎn),并且使用點(diǎn)(.)運(yùn)算發(fā)可以獲取子節(jié)點(diǎn)元素。通過瀏覽器得到的搜索內(nèi)容皆為鏈接,點(diǎn)擊可跳轉(zhuǎn),那么只需要獲取每一個元素下的a標(biāo)簽即可:
for el in search_res_list:
print(el.a)
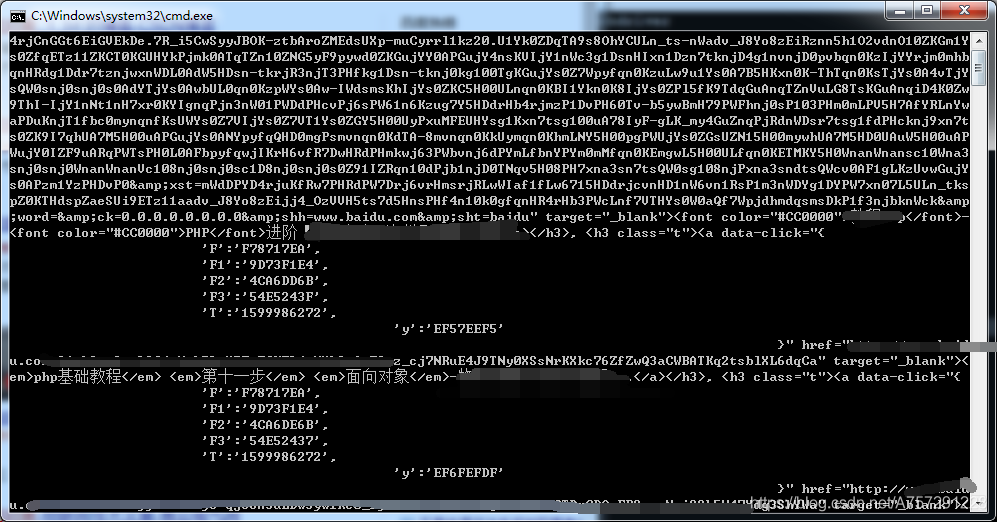
從結(jié)果中很明顯的看出搜索結(jié)果的a標(biāo)簽已經(jīng)獲取,那么接下來我們需要的是提取每個a標(biāo)簽內(nèi)的href超鏈接。獲取href超鏈接直接使用列表獲取元素的方式獲取即可:
for el in search_res_list:
print(el.a['href'])
運(yùn)行腳本成功得到結(jié)果:
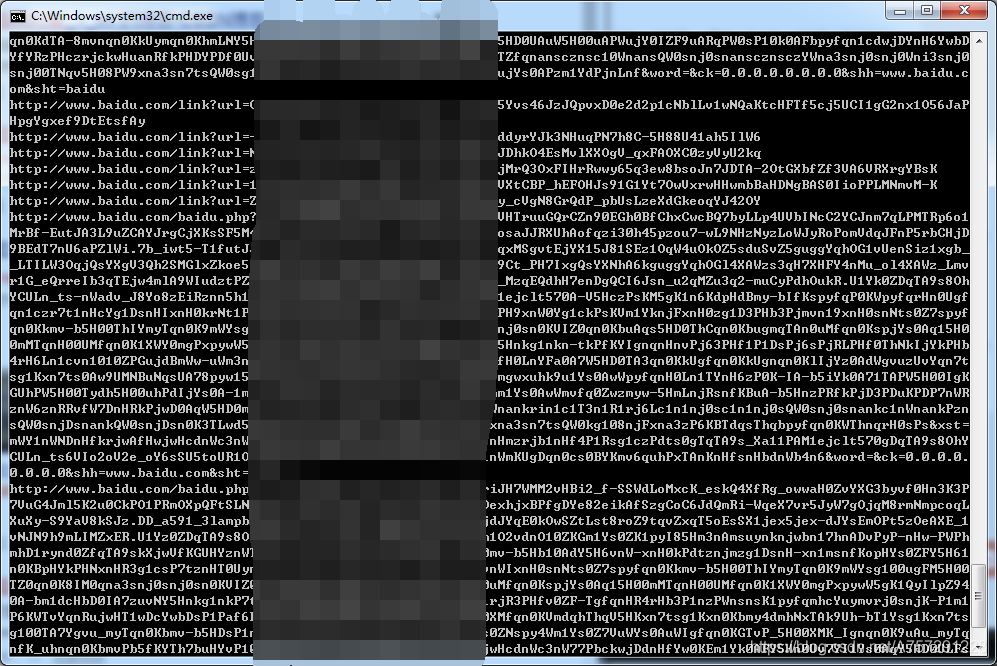
細(xì)心的讀者可能會發(fā)現(xiàn),這些獲取到的結(jié)果中,都是baidu的網(wǎng)址。其實(shí)這些網(wǎng)址可以說是“索引”,通過這些索引再次跳轉(zhuǎn)到真實(shí)網(wǎng)址。由于這些“索引”不一定會變動,并不利于長期存儲,在此還是需要獲取到真實(shí)的鏈接。
我們調(diào)用js腳本對這些網(wǎng)址進(jìn)行訪問,這些網(wǎng)址將會跳轉(zhuǎn)到真實(shí)網(wǎng)址,跳轉(zhuǎn)后再獲取當(dāng)前的網(wǎng)址信息即可。調(diào)用execute_script方法可執(zhí)行js代碼,代碼如下:
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
driver.execute_script(js)
打開新的網(wǎng)頁后,需要獲取新網(wǎng)頁的句柄,否則無法操控新網(wǎng)頁。獲取句柄的方法如下:
handle_this=driver.current_window_handle#獲取當(dāng)前句柄
handle_all=driver.window_handles#獲取所有句柄
獲取句柄后需要把當(dāng)前操作的對象切換成新的頁面。由于打開一個頁面后所有頁面只有2個,簡單的使用遍歷做一個替換:
handle_exchange=None#要切換的句柄
for handle in handle_all:#不匹配為新句柄
if handle != handle_this:#不等于當(dāng)前句柄就交換
handle_exchange = handle
driver.switch_to.window(handle_exchange)#切換
切換后,操作對象為當(dāng)前剛打開的頁面。通過current_url屬性拿到新頁面的url:
real_url=driver.current_url
print(real_url)
隨后關(guān)閉當(dāng)前頁面,把操作對象置為初始頁面:
driver.close()
driver.switch_to.window(handle_this)#換回最初始界面
運(yùn)行腳本成功獲取到真實(shí)url:
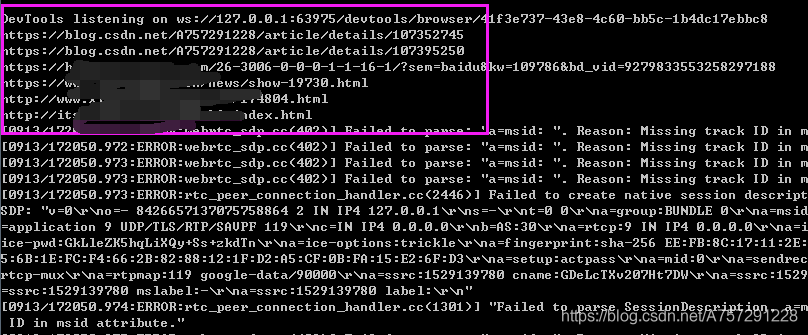
最后在獲取到真實(shí)url后使用一個列表將結(jié)果存儲:
real_url_list.append(real_url)
這一部分完整代碼如下:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
url='https://www.baidu.com'
driver=webdriver.Chrome()
driver.get(url)
input=driver.find_element_by_id('kw')
input.send_keys('php基礎(chǔ)教程 第十一步 面向?qū)ο?)
search_btn=driver.find_element_by_id('su')
search_btn.click()
time.sleep(2)#在此等待 使瀏覽器解析并渲染到瀏覽器
html=driver.page_source
soup = BeautifulSoup(html, "html.parser")
search_res_list=soup.select('.t')
real_url_list=[]
# print(search_res_list)
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
driver.execute_script(js)
handle_this=driver.current_window_handle#獲取當(dāng)前句柄
handle_all=driver.window_handles#獲取所有句柄
handle_exchange=None#要切換的句柄
for handle in handle_all:#不匹配為新句柄
if handle != handle_this:#不等于當(dāng)前句柄就交換
handle_exchange = handle
driver.switch_to.window(handle_exchange)#切換
real_url=driver.current_url
print(real_url)
real_url_list.append(real_url)#存儲結(jié)果
driver.close()
driver.switch_to.window(handle_this)
1.4 獲取源文本
在當(dāng)前文件的目錄下新建一個文件夾,命名為textsrc,在該目錄下創(chuàng)建一個txt文件,把需要對比的文本存放至該文本中。在此我存放的內(nèi)容為文章“php基礎(chǔ)教程 第十一步 面向?qū)ο?/strong>”的內(nèi)容。
在代碼中編寫一個函數(shù)為獲取文本內(nèi)容:
def read_txt(path=''):
f = open(path,'r')
return f.read()
src=read_txt(r'F:\tool\textsrc\src.txt')
為了方便測試,這里使用是絕對路徑。
獲取到文本內(nèi)容后,編寫余弦相似度的對比方法。
1.5 余弦相似度
相似度計(jì)算參考文章《python實(shí)現(xiàn)余弦相似度文本比較》,本人修改一部分從而實(shí)現(xiàn)。
本文相似度對比使用余弦相似度算法,一般步驟分為分詞->向量計(jì)算->計(jì)算相似度。
新建一個python文件,名為Analyse。新建一個類名為Analyse,在類中添加分詞方法,并在頭部引入jieba分詞庫,以及collections統(tǒng)計(jì)次數(shù):
from jieba import lcut
import jieba.analyse
import collections
Count方法:
#分詞
def Count(self,text):
tag = jieba.analyse.textrank(text,topK=20)
word_counts = collections.Counter(tag) #計(jì)數(shù)統(tǒng)計(jì)
return word_counts
Count方法接收一個text變量,text變量為文本,使用textrank方法分詞并且使用Counter計(jì)數(shù)。
隨后添加MergeWord方法,使詞合并方便之后的向量計(jì)算:
#詞合并
def MergeWord(self,T1,T2):
MergeWord = []
for i in T1:
MergeWord.append(i)
for i in T2:
if i not in MergeWord:
MergeWord.append(i)
return MergeWord
合并方法很簡單不再做解釋。接下來添加向量計(jì)算方法:
# 得出文檔向量
def CalVector(self,T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in T1:
TermFrequence = T1[ch]
word = ch
if word in MergeWord:
TF1[MergeWord.index(word)] = TermFrequence
return TF1
最后添加相似度計(jì)算方法:
def cosine_similarity(self,vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):#兩個向量組合成 [(1, 4), (2, 5), (3, 6)] 最短形式表現(xiàn)
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5))*100, 2)
相似度方法接收兩個向量,隨后計(jì)算相似度并返回。為了代碼冗余度少,在這里先簡單的添加一個方法,完成計(jì)算流程:
def get_Tfidf(self,text1,text2):#測試對比本地?cái)?shù)據(jù)對比搜索引擎方法
# self.correlate.word.set_this_url(url)
T1 = self.Count(text1)
T2 = self.Count(text2)
mergeword = self.MergeWord(T1,T2)
return self.cosine_similarity(self.CalVector(T1,mergeword),self.CalVector(T2,mergeword))
Analyse類的完整代碼如下:
from jieba import lcut
import jieba.analyse
import collections
class Analyse:
def get_Tfidf(self,text1,text2):#測試對比本地?cái)?shù)據(jù)對比搜索引擎方法
# self.correlate.word.set_this_url(url)
T1 = self.Count(text1)
T2 = self.Count(text2)
mergeword = self.MergeWord(T1,T2)
return self.cosine_similarity(self.CalVector(T1,mergeword),self.CalVector(T2,mergeword))
#分詞
def Count(self,text):
tag = jieba.analyse.textrank(text,topK=20)
word_counts = collections.Counter(tag) #計(jì)數(shù)統(tǒng)計(jì)
return word_counts
#詞合并
def MergeWord(self,T1,T2):
MergeWord = []
for i in T1:
MergeWord.append(i)
for i in T2:
if i not in MergeWord:
MergeWord.append(i)
return MergeWord
# 得出文檔向量
def CalVector(self,T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in T1:
TermFrequence = T1[ch]
word = ch
if word in MergeWord:
TF1[MergeWord.index(word)] = TermFrequence
return TF1
#計(jì)算 TF-IDF
def cosine_similarity(self,vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):#兩個向量組合成 [(1, 4), (2, 5), (3, 6)] 最短形式表現(xiàn)
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5))*100, 2)
1.6 搜索結(jié)果內(nèi)容與文本做相似度對比
在selenium_search文件中引入Analyse,并且新建對象:
from Analyse import Analyse
Analyse=Analyse()
在遍歷搜索結(jié)果中添加獲取新打開后的頁面的網(wǎng)頁內(nèi)容:
time.sleep(5)
html_2=driver.page_source
使用 time.sleep(5)是為了等待瀏覽器能夠有時間渲染當(dāng)前web內(nèi)容。獲取到新打開的頁面內(nèi)容后,進(jìn)行相似度對比:
Analyse.get_Tfidf(src,html_2)
由于返回的是一個值,使用print輸出:
print('相似度:',Analyse.get_Tfidf(src,html_2))
完整代碼如下:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
from Analyse import Analyse
def read_txt(path=''):
f = open(path,'r')
return f.read()
#獲取對比文件
src=read_txt(r'F:\tool\textsrc\src.txt')
Analyse=Analyse()
url='https://www.baidu.com'
driver=webdriver.Chrome()
driver.get(url)
input=driver.find_element_by_id('kw')
input.send_keys('php基礎(chǔ)教程 第十一步 面向?qū)ο?)
search_btn=driver.find_element_by_id('su')
search_btn.click()
time.sleep(2)#在此等待 使瀏覽器解析并渲染到瀏覽器
html=driver.page_source
soup = BeautifulSoup(html, "html.parser")
search_res_list=soup.select('.t')
real_url_list=[]
# print(search_res_list)
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
driver.execute_script(js)
handle_this=driver.current_window_handle#獲取當(dāng)前句柄
handle_all=driver.window_handles#獲取所有句柄
handle_exchange=None#要切換的句柄
for handle in handle_all:#不匹配為新句柄
if handle != handle_this:#不等于當(dāng)前句柄就交換
handle_exchange = handle
driver.switch_to.window(handle_exchange)#切換
real_url=driver.current_url
time.sleep(5)
html_2=driver.page_source
print('相似度:',Analyse.get_Tfidf(src,html_2))
print(real_url)
real_url_list.append(real_url)
driver.close()
driver.switch_to.window(handle_this)
運(yùn)行腳本:
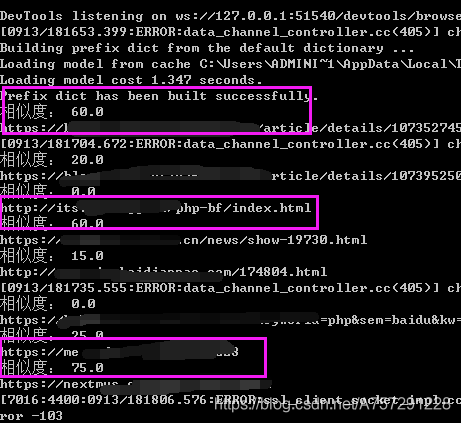
結(jié)果顯示有幾個高度相似的鏈接,那么這幾個就是疑似抄襲的文章了。
以上是完成基本查重的代碼,但是相對于說代碼比較冗余、雜亂,接下來我們優(yōu)化一下代碼。
二、代碼優(yōu)化
通過以上的程序編程,簡要步驟可以分為:獲取搜索內(nèi)容->獲取結(jié)果->計(jì)算相似度。我們可以新建三個類,分別為:Browser、Analyse(已新建)、SearchEngine。
Browser用于搜索、數(shù)據(jù)獲取等;Analyse用于相似度分析、向量計(jì)算等;SearchEngine用于不同搜索引擎的基本配置,因?yàn)榇蟛糠炙讯嘁娴乃阉鞣绞捷^為一致。
2.1Browser 類
初始化
新建一個python文件,名為Browser,添加初始化方法:
def __init__(self,conf):
self.browser=webdriver.Chrome()
self.conf=conf
self.engine_conf=EngineConfManage().get_Engine_conf(conf['engine']).get_conf()
self.browser=webdriver.Chrome()為新建一個瀏覽器對象;conf為傳入的搜索配置,之后進(jìn)行搜索內(nèi)容由編寫配置字典實(shí)現(xiàn);self.engine_conf=EngineConfManage().get_Engine_conf(conf['engine']).get_conf()為獲取搜索引擎的配置,不同搜索引擎的輸入框、搜索按鍵不一致,通過不同的配置信息實(shí)現(xiàn)多搜索引擎搜索。
添加搜索方法
#搜索內(nèi)容寫入到搜素引擎中
def send_keyword(self):
input = self.browser.find_element_by_id(self.engine_conf['searchTextID'])
input.send_keys(self.conf['kw'])
以上方法中self.engine_conf['searchTextID']與self.conf['kw']通過初始化方法得到對應(yīng)的搜索引擎配置信息,直接獲取信息得到元素。
點(diǎn)擊搜索
#搜索框點(diǎn)擊
def click_search_btn(self):
search_btn = self.browser.find_element_by_id(self.engine_conf['searchBtnID'])
search_btn.click()
通過使用self.engine_conf['searchBtnID']獲取搜索按鈕的id。
獲取搜索結(jié)果與文本
#獲取搜索結(jié)果與文本
def get_search_res_url(self):
res_link={}
WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))
#內(nèi)容通過 BeautifulSoup 解析
content=self.browser.page_source
soup = BeautifulSoup(content, "html.parser")
search_res_list=soup.select('.'+self.engine_conf['searchContentHref_class'])
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
self.browser.execute_script(js)
handle_this=self.browser.current_window_handle #獲取當(dāng)前句柄
handle_all=self.browser.window_handles #獲取所有句柄
handle_exchange=None #要切換的句柄
for handle in handle_all: #不匹配為新句柄
if handle != handle_this: #不等于當(dāng)前句柄就交換
handle_exchange = handle
self.browser.switch_to.window(handle_exchange) #切換
real_url=self.browser.current_url
time.sleep(1)
res_link[real_url]=self.browser.page_source #結(jié)果獲取
self.browser.close()
self.browser.switch_to.window(handle_this)
return res_link
以上方法跟之前編寫的遍歷搜索結(jié)果內(nèi)容相似,從中添加了WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))替代了sleep,用于判斷EC.presence_of_element_located((By.ID, "page"))是否找到id值為page的網(wǎng)頁元素,id為page的網(wǎng)頁元素為分頁按鈕的標(biāo)簽id,如果未獲取表示當(dāng)前web頁并未加載完全,等待時間為timeout=3030秒,如果已過去則跳過等待。
以上代碼中并不做相似度對比,而是通過 res_link[real_url]=self.browser.page_source 將內(nèi)容與url存入字典,隨后返回,之后再做相似度對比,這樣編寫利于之后的功能擴(kuò)展。
打開目標(biāo)搜索引擎進(jìn)行搜索
#打開目標(biāo)搜索引擎進(jìn)行搜索
def search(self):
self.browser.get(self.engine_conf['website']) #打開搜索引擎站點(diǎn)
self.send_keyword() #輸入搜索kw
self.click_search_btn() #點(diǎn)擊搜索
return self.get_search_res_url() #獲取web頁搜索數(shù)據(jù)
最后添加一個search方法,直接調(diào)用search方法即可實(shí)現(xiàn)之前的所有操作,不用暴露過多簡化使用。
完整代碼如下:
from selenium import webdriver
from bs4 import BeautifulSoup
from SearchEngine import EngineConfManage
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
class Browser:
def __init__(self,conf):
self.browser=webdriver.Chrome()
self.conf=conf
self.engine_conf=EngineConfManage().get_Engine_conf(conf['engine']).get_conf()
#搜索內(nèi)容寫入到搜素引擎中
def send_keyword(self):
input = self.browser.find_element_by_id(self.engine_conf['searchTextID'])
input.send_keys(self.conf['kw'])
#搜索框點(diǎn)擊
def click_search_btn(self):
search_btn = self.browser.find_element_by_id(self.engine_conf['searchBtnID'])
search_btn.click()
#獲取搜索結(jié)果與文本
def get_search_res_url(self):
res_link={}
WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))
#內(nèi)容通過 BeautifulSoup 解析
content=self.browser.page_source
soup = BeautifulSoup(content, "html.parser")
search_res_list=soup.select('.'+self.engine_conf['searchContentHref_class'])
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
self.browser.execute_script(js)
handle_this=self.browser.current_window_handle #獲取當(dāng)前句柄
handle_all=self.browser.window_handles #獲取所有句柄
handle_exchange=None #要切換的句柄
for handle in handle_all: #不匹配為新句柄
if handle != handle_this: #不等于當(dāng)前句柄就交換
handle_exchange = handle
self.browser.switch_to.window(handle_exchange) #切換
real_url=self.browser.current_url
time.sleep(1)
res_link[real_url]=self.browser.page_source #結(jié)果獲取
self.browser.close()
self.browser.switch_to.window(handle_this)
return res_link
#打開目標(biāo)搜索引擎進(jìn)行搜索
def search(self):
self.browser.get(self.engine_conf['website']) #打開搜索引擎站點(diǎn)
self.send_keyword() #輸入搜索kw
self.click_search_btn() #點(diǎn)擊搜索
return self.get_search_res_url() #獲取web頁搜索數(shù)據(jù)
2.2SearchEngine 類
SearchEngine類主要用于不同搜索引擎的配置編寫。更加簡便的實(shí)現(xiàn)搜索引擎或相似業(yè)務(wù)的擴(kuò)展。
#搜索引擎配置
class EngineConfManage:
def get_Engine_conf(self,engine_name):
if engine_name=='baidu':
return BaiduEngineConf()
elif engine_name=='qihu360':
return Qihu360EngineConf()
elif engine_name=='sougou':
return SougouEngineConf()
class EngineConf:
def __init__(self):
self.engineConf={}
def get_conf(self):
return self.engineConf
class BaiduEngineConf(EngineConf):
engineConf={}
def __init__(self):
self.engineConf['searchTextID']='kw'
self.engineConf['searchBtnID']='su'
self.engineConf['nextPageBtnID_xpath_f']='//*[@id="page"]/div/a[10]'
self.engineConf['nextPageBtnID_xpath_s']='//*[@id="page"]/div/a[11]'
self.engineConf['searchContentHref_class']='t'
self.engineConf['website']='http://www.baidu.com'
class Qihu360EngineConf(EngineConf):
def __init__(self):
pass
class SougouEngineConf(EngineConf):
def __init__(self):
pass
在此只實(shí)現(xiàn)了百度搜索引擎的配置編寫。所有不同種類的搜索引擎繼承EngineConf基類,使子類都有了get_conf方法。EngineConfManage類用于不同搜索引擎的調(diào)用,傳入引擎名即可。
2.3如何使用
首先引入兩個類:
from Browser import Browser
from Analyse import Analyse
新建一個方法讀取本地文件:
def read_txt(path=''):
f = open(path,'r')
return f.read()
獲取文件并新建數(shù)據(jù)分析類:
src=read_txt(r'F:\tool\textsrc\src.txt')#獲取本地文本
Analyse=Analyse()
配置信息字典編寫:
#配置信息
conf={
'kw':'php基礎(chǔ)教程 第十一步 面向?qū)ο?,
'engine':'baidu',
}
新建Browser類,并傳入配置信息:
獲取搜索結(jié)果及內(nèi)容
url_content=drvier.search()#獲取搜索結(jié)果及內(nèi)容
遍歷結(jié)果及計(jì)算相似度:
for k in url_content:
print(k,'相似度:',Analyse.get_Tfidf(src,url_content[k]))
完整代碼如下:
from Browser import Browser
from Analyse import Analyse
def read_txt(path=''):
f = open(path,'r')
return f.read()
src=read_txt(r'F:\tool\textsrc\src.txt')#獲取本地文本
Analyse=Analyse()
#配置信息
conf={
'kw':'php基礎(chǔ)教程 第十一步 面向?qū)ο?,
'engine':'baidu',
}
drvier=Browser(conf)
url_content=drvier.search()#獲取搜索結(jié)果及內(nèi)容
for k in url_content:
print(k,'相似度:',Analyse.get_Tfidf(src,url_content[k]))
是不是感覺舒服多了?簡直不要太清爽。你以為這就完了嗎?還沒完,接下來擴(kuò)展一下功能。
三、功能擴(kuò)展
暫時這個小工具的功能只有查重這個基礎(chǔ)功能,并且這個存在很多問題。如沒有白名單過濾、只能查一篇文章的相似度、如果比較懶也沒有直接獲取文章列表自動查重的功能以及結(jié)果導(dǎo)出等。接下來慢慢完善部分功能,由于篇幅關(guān)系并不完全把的功能實(shí)現(xiàn)在此列出,之后將會持續(xù)更新。
3.1自動獲取文本
新建一個python文件,名為FileHandle。該類用于自動獲取指定目錄下txt文件,txt文件文件名為關(guān)鍵字,內(nèi)容為該名稱的文章內(nèi)容。類代碼如下:
import os
class FileHandle:
#獲取文件內(nèi)容
def get_content(self,path):
f = open(path,"r") #設(shè)置文件對象
content = f.read() #將txt文件的所有內(nèi)容讀入到字符串str中
f.close() #將文件關(guān)閉
return content
#獲取文件內(nèi)容
def get_text(self):
file_path=os.path.dirname(__file__) #當(dāng)前文件所在目錄
txt_path=file_path+r'\textsrc' #txt目錄
rootdir=os.path.join(txt_path) #目標(biāo)目錄內(nèi)容
local_text={}
# 讀txt 文件
for (dirpath,dirnames,filenames) in os.walk(rootdir):
for filename in filenames:
if os.path.splitext(filename)[1]=='.txt':
flag_file_path=dirpath+'\\'+filename #文件路徑
flag_file_content=self.get_content(flag_file_path) #讀文件路徑
if flag_file_content!='':
local_text[filename.replace('.txt', '')]=flag_file_content #鍵值對內(nèi)容
return local_text
其中有兩個方法get_content與get_text。get_text為獲取目錄下所有txt文件路徑,通過get_content獲取到詳細(xì)文本內(nèi)容,返回local_text;local_text鍵為文件名,值為文本內(nèi)容。
3.2BrowserManage類
在Browser類文件中添加一個BrowserManage類繼承于Browser,添加方法:
#打開目標(biāo)搜索引擎進(jìn)行搜索
def search(self):
self.browser.get(self.engine_conf['website']) #打開搜索引擎站點(diǎn)
self.send_keyword() #輸入搜索kw
self.click_search_btn() #點(diǎn)擊搜索
return self.get_search_res_url() #獲取web頁搜索數(shù)據(jù)
添加該類使Browser類的邏輯與其它方法分開,便于擴(kuò)展。
3.3Browser類的擴(kuò)展
在Browser類中添加下一頁方法,使搜索內(nèi)容時能夠獲取更多內(nèi)容,并且可指定獲取結(jié)果條數(shù):
#下一頁
def click_next_page(self,md5):
WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))
#百度搜索引擎翻頁后下一頁按鈕 xpath 不一致 默認(rèn)非第一頁xpath
try:
next_page_btn = self.browser.find_element_by_xpath(self.engine_conf['nextPageBtnID_xpath_s'])
except:
next_page_btn = self.browser.find_element_by_xpath(self.engine_conf['nextPageBtnID_xpath_f'])
next_page_btn.click()
#md5 進(jìn)行 webpag text 對比,判斷是否已翻頁 (暫時使用,存在bug)
i=0
while md5==hashlib.md5(self.browser.page_source.encode(encoding='UTF-8')).hexdigest():#md5 對比
time.sleep(0.3)#防止一些錯誤,暫時使用強(qiáng)制停止保持一些穩(wěn)定
i+=1
if i>100:
return False
return True
百度搜索引擎翻頁后下一頁按鈕 xpath 不一致 默認(rèn)非第一頁xpath,出現(xiàn)異常使用另外一個xpath。隨后對頁面進(jìn)行md5,對比md5值,如果當(dāng)前頁面沒有刷新,md5值將不會改變,等待小短時間之后點(diǎn)擊下一頁。
3.4get_search_res_url方法的修改
get_search_res_url方法的修改了部分內(nèi)容,添加了增加結(jié)果條數(shù)指定、下一頁內(nèi)容獲取以及白名單設(shè)置更改過后的代碼如下:
#獲取搜索結(jié)果與文本
def get_search_res_url(self):
res_link={}
WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))
#內(nèi)容通過 BeautifulSoup 解析
content=self.browser.page_source
soup = BeautifulSoup(content, "html.parser")
search_res_list=soup.select('.'+self.engine_conf['searchContentHref_class'])
while len(res_link)self.conf['target_page']:
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
self.browser.execute_script(js)
handle_this=self.browser.current_window_handle #獲取當(dāng)前句柄
handle_all=self.browser.window_handles #獲取所有句柄
handle_exchange=None #要切換的句柄
for handle in handle_all: #不匹配為新句柄
if handle != handle_this: #不等于當(dāng)前句柄就交換
handle_exchange = handle
self.browser.switch_to.window(handle_exchange) #切換
real_url=self.browser.current_url
if real_url in self.conf['white_list']: #白名單
continue
time.sleep(1)
res_link[real_url]=self.browser.page_source #結(jié)果獲取
self.browser.close()
self.browser.switch_to.window(handle_this)
content_md5=hashlib.md5(self.browser.page_source.encode(encoding='UTF-8')).hexdigest() #md5對比
self.click_next_page(content_md5)
return res_link
while len(res_link)self.conf['target_page']:為增加了對結(jié)果條數(shù)的判斷。
content_md5=hashlib.md5(self.browser.page_source.encode(encoding='UTF-8')).hexdigest() #md5對比
self.click_next_page(content_md5)
以上代碼增加了當(dāng)前頁面刷新后的md5值判斷,不一致則進(jìn)行跳轉(zhuǎn)。
if real_url in self.conf['white_list']: #白名單
continue
以上代碼對白名單進(jìn)行了判斷,自己設(shè)置的白名單不加入到條數(shù)。
3.5新建Manage類
新建一python文件名為Manage,再次封裝。代碼如下:
from Browser import BrowserManage
from Analyse import Analyse
from FileHandle import FileHandle
class Manage:
def __init__(self,conf):
self.drvier=BrowserManage(conf)
self.textdic=FileHandle().get_text()
self.analyse=Analyse()
def get_local_analyse(self):
resdic={}
for k in self.textdic:
res={}
self.drvier.set_kw(k)
url_content=self.drvier.search()#獲取搜索結(jié)果及內(nèi)容
for k1 in url_content:
res[k1]=self.analyse.get_Tfidf(self.textdic[k],url_content[k1])
resdic[k]=res
return resdic
以上代碼初始化方法接收一個參數(shù),且初始化方法中新建了BrowserManage對象、Analyse對象以及獲取了文本內(nèi)容。
get_local_analyse方法遍歷文本,使用文件名當(dāng)作關(guān)鍵字進(jìn)行搜索,并且將搜索內(nèi)容與當(dāng)前文本做相似度對比,最后返回結(jié)果。
結(jié)果如下:
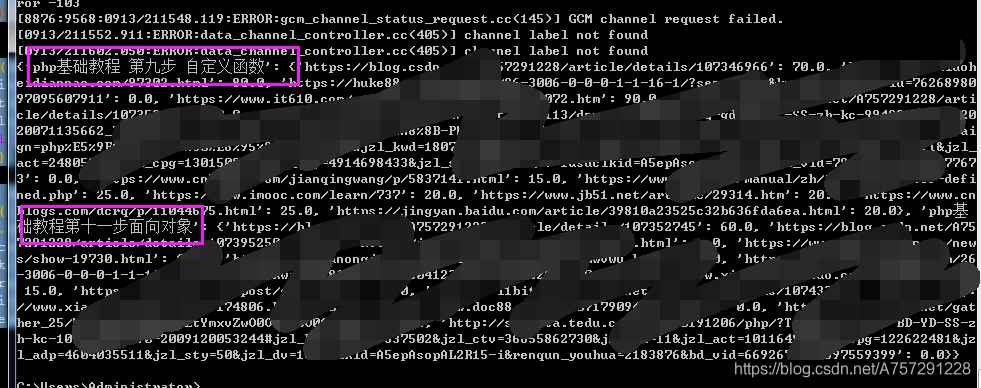
博主目錄下文件如下:
相似度分析部分以上為主要內(nèi)容,工具之后將會丟GitHub及csdn的代碼倉庫中,使用的無頭模式,本篇所講的內(nèi)容為一般實(shí)現(xiàn)。
所有完整的代碼如下
Analyse類:
from jieba import lcut
import jieba.analyse
import collections
from FileHandle import FileHandle
class Analyse:
def get_Tfidf(self,text1,text2):#測試對比本地?cái)?shù)據(jù)對比搜索引擎方法
# self.correlate.word.set_this_url(url)
T1 = self.Count(text1)
T2 = self.Count(text2)
mergeword = self.MergeWord(T1,T2)
return self.cosine_similarity(self.CalVector(T1,mergeword),self.CalVector(T2,mergeword))
#分詞
def Count(self,text):
tag = jieba.analyse.textrank(text,topK=20)
word_counts = collections.Counter(tag) #計(jì)數(shù)統(tǒng)計(jì)
return word_counts
#詞合并
def MergeWord(self,T1,T2):
MergeWord = []
for i in T1:
MergeWord.append(i)
for i in T2:
if i not in MergeWord:
MergeWord.append(i)
return MergeWord
# 得出文檔向量
def CalVector(self,T1,MergeWord):
TF1 = [0] * len(MergeWord)
for ch in T1:
TermFrequence = T1[ch]
word = ch
if word in MergeWord:
TF1[MergeWord.index(word)] = TermFrequence
return TF1
#計(jì)算 TF-IDF
def cosine_similarity(self,vector1, vector2):
dot_product = 0.0
normA = 0.0
normB = 0.0
for a, b in zip(vector1, vector2):#兩個向量組合成 [(1, 4), (2, 5), (3, 6)] 最短形式表現(xiàn)
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return 0
else:
return round(dot_product / ((normA**0.5)*(normB**0.5))*100, 2)
Browser類:
from selenium import webdriver
from bs4 import BeautifulSoup
from SearchEngine import EngineConfManage
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import hashlib
import time
import xlwt
class Browser:
def __init__(self,conf):
self.browser=webdriver.Chrome()
self.conf=conf
self.conf['kw']=''
self.engine_conf=EngineConfManage().get_Engine_conf(conf['engine']).get_conf()
#搜索內(nèi)容設(shè)置
def set_kw(self,kw):
self.conf['kw']=kw
#搜索內(nèi)容寫入到搜素引擎中
def send_keyword(self):
input = self.browser.find_element_by_id(self.engine_conf['searchTextID'])
input.send_keys(self.conf['kw'])
#搜索框點(diǎn)擊
def click_search_btn(self):
search_btn = self.browser.find_element_by_id(self.engine_conf['searchBtnID'])
search_btn.click()
#獲取搜索結(jié)果與文本
def get_search_res_url(self):
res_link={}
WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))
#內(nèi)容通過 BeautifulSoup 解析
content=self.browser.page_source
soup = BeautifulSoup(content, "html.parser")
search_res_list=soup.select('.'+self.engine_conf['searchContentHref_class'])
while len(res_link)self.conf['target_page']:
for el in search_res_list:
js = 'window.open("'+el.a['href']+'")'
self.browser.execute_script(js)
handle_this=self.browser.current_window_handle #獲取當(dāng)前句柄
handle_all=self.browser.window_handles #獲取所有句柄
handle_exchange=None #要切換的句柄
for handle in handle_all: #不匹配為新句柄
if handle != handle_this: #不等于當(dāng)前句柄就交換
handle_exchange = handle
self.browser.switch_to.window(handle_exchange) #切換
real_url=self.browser.current_url
if real_url in self.conf['white_list']: #白名單
continue
time.sleep(1)
res_link[real_url]=self.browser.page_source #結(jié)果獲取
self.browser.close()
self.browser.switch_to.window(handle_this)
content_md5=hashlib.md5(self.browser.page_source.encode(encoding='UTF-8')).hexdigest() #md5對比
self.click_next_page(content_md5)
return res_link
#下一頁
def click_next_page(self,md5):
WebDriverWait(self.browser,timeout=30,poll_frequency=1).until(EC.presence_of_element_located((By.ID, "page")))
#百度搜索引擎翻頁后下一頁按鈕 xpath 不一致 默認(rèn)非第一頁xpath
try:
next_page_btn = self.browser.find_element_by_xpath(self.engine_conf['nextPageBtnID_xpath_s'])
except:
next_page_btn = self.browser.find_element_by_xpath(self.engine_conf['nextPageBtnID_xpath_f'])
next_page_btn.click()
#md5 進(jìn)行 webpag text 對比,判斷是否已翻頁 (暫時使用,存在bug)
i=0
while md5==hashlib.md5(self.browser.page_source.encode(encoding='UTF-8')).hexdigest():#md5 對比
time.sleep(0.3)#防止一些錯誤,暫時使用強(qiáng)制停止保持一些穩(wěn)定
i+=1
if i>100:
return False
return True
class BrowserManage(Browser):
#打開目標(biāo)搜索引擎進(jìn)行搜索
def search(self):
self.browser.get(self.engine_conf['website']) #打開搜索引擎站點(diǎn)
self.send_keyword() #輸入搜索kw
self.click_search_btn() #點(diǎn)擊搜索
return self.get_search_res_url() #獲取web頁搜索數(shù)據(jù)
Manage類:
from Browser import BrowserManage
from Analyse import Analyse
from FileHandle import FileHandle
class Manage:
def __init__(self,conf):
self.drvier=BrowserManage(conf)
self.textdic=FileHandle().get_text()
self.analyse=Analyse()
def get_local_analyse(self):
resdic={}
for k in self.textdic:
res={}
self.drvier.set_kw(k)
url_content=self.drvier.search()#獲取搜索結(jié)果及內(nèi)容
for k1 in url_content:
res[k1]=self.analyse.get_Tfidf(self.textdic[k],url_content[k1])
resdic[k]=res
return resdic
FileHandle類:
import os
class FileHandle:
#獲取文件內(nèi)容
def get_content(self,path):
f = open(path,"r") #設(shè)置文件對象
content = f.read() #將txt文件的所有內(nèi)容讀入到字符串str中
f.close() #將文件關(guān)閉
return content
#獲取文件內(nèi)容
def get_text(self):
file_path=os.path.dirname(__file__) #當(dāng)前文件所在目錄
txt_path=file_path+r'\textsrc' #txt目錄
rootdir=os.path.join(txt_path) #目標(biāo)目錄內(nèi)容
local_text={}
# 讀txt 文件
for (dirpath,dirnames,filenames) in os.walk(rootdir):
for filename in filenames:
if os.path.splitext(filename)[1]=='.txt':
flag_file_path=dirpath+'\\'+filename #文件路徑
flag_file_content=self.get_content(flag_file_path) #讀文件路徑
if flag_file_content!='':
local_text[filename.replace('.txt', '')]=flag_file_content #鍵值對內(nèi)容
return local_text
本文最終使用方法如下:
from Manage import Manage
white_list=['blog.csdn.net/A757291228','www.cnblogs.com/1-bit','blog.csdn.net/csdnnews']#白名單
#配置信息
conf={
'engine':'baidu',
'target_page':5
'white_list':white_list,
}
print(Manage(conf).get_local_analyse())
到此這篇關(guān)于python基于搜索引擎實(shí)現(xiàn)文章查重功能的文章就介紹到這了,更多相關(guān)python文章查重內(nèi)容請搜索腳本之家以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持腳本之家!
您可能感興趣的文章:- Mysql實(shí)現(xiàn)簡易版搜索引擎的示例代碼
- MySQL全文索引實(shí)現(xiàn)簡單版搜索引擎實(shí)例代碼
- 詳細(xì)介紹基于MySQL的搜索引擎MySQL-Fullltext
- scrapy+flask+html打造搜索引擎的示例代碼
- Python實(shí)戰(zhàn)之手寫一個搜索引擎
- Python大批量搜索引擎圖像爬蟲工具詳解
- 360搜索引擎自動收錄php改寫方案
- php記錄搜索引擎爬行記錄的實(shí)現(xiàn)代碼
- Python無損音樂搜索引擎實(shí)現(xiàn)代碼
- 基于 Mysql 實(shí)現(xiàn)一個簡易版搜索引擎
